
The Joy of Randomness: Reclaiming Serendipity in an Optimized World
Recommendation systems are extraordinarily good at predicting what we will do next.
But increasingly bad at surprising us.
There’s a fundamental tension between systems built to optimize and humans who resist being optimized. If you want to change it, you need to introduce entropy into the system.
For example, I like romantic comedies, Netflix recommended a romantic comedy, I watched it, I liked it, Netflix will recommend a romantic comedy next time. Given my past behavior, it makes sense as Netflix is trying to maximize my engagement with their platform. But I know I’d like to see recommendations for foreign films that never show up.
Recommendation systems don’t define us. Whether it’s Amazon, Netflix, Apple news feeds, Facebook posts, or Spotify playlists, they are all trying to optimize us. They are not optimizing for truth, diversity, or our long-term enlightenment, but instead for engagement, retention, revenue, and lifetime value.
These recommendation systems are designed to aid us as we navigate the world. They work on our behalf to sift through the overwhelming volume of data to find what’s likely to align with our needs and wants. It’s about efficiency, relevance, and accuracy. None of us could sift through all of the movies ever made to find the one we want to watch (though some Friday nights it might feel like we’re doing that).
The key word is likely. Recommendations are probabilistic, not deterministic. We intuitively recognize this probability when we are halfway through a Netflix recommendation and turn it off because it’s a dog.
How Recommendation Systems Actually Work
First, they collect massive amounts of historical behavior data. Then, they identify patterns across millions (or billions) of users / subscribers.
They capture our behavioral residue. By comparing us to others, they try to predict what we’re most likely to engage with next. It’s a probability distribution.
Most modern recommendation systems use Hybrid Models, which means they combine different types of algorithms and filtering to make those recommendations. Using Netflix as an example, possible types of models might include:
- Collaborative Filtering – the wisdom of the crowd. If you and I both like Interstellar and I watched and liked Stranger Things, it predicts you’ll like it too.
- Content-based filtering -the DNA match. You liked The Pitt, so it looks for other emergency room dramas.
- Deep Learning Models – the pattern recognizer. They are large neural networks that learn complex patterns from data, including everything about you and the movies.
- Reinforcement learning – the feedback loop. It learns from your interactions with a movie and adapts going forward.
- Contextual signals – the right now and here. The system makes recommendations based on time of day, device, and location. For example, it knows you want a 20-minute documentary on your phone at 8 am (it doesn’t know you’re taking the subway to work).
To understand how recommendation engines match you to a movie, you need to understand that both you and the movie exist as vectors in a high-dimensional embedding space.
That’s a concept that’s tough to get our minds around, so let me break it down.
For simplicity and efficiency, every learned feature about you and the movie has been converted to numbers. These features might include innumerable preferences including your perceived affinity for westerns, dialogue quality, moral ambiguity of the protagonist, dirty-brown haired female heroines with blue-gray eyes, etc. Similarly, the movie has been converted to a vector (set of numbers). To be clear, the model discovers these categories (statistical patterns) on its own when it’s trained and the vectors would look like gibberish to us.
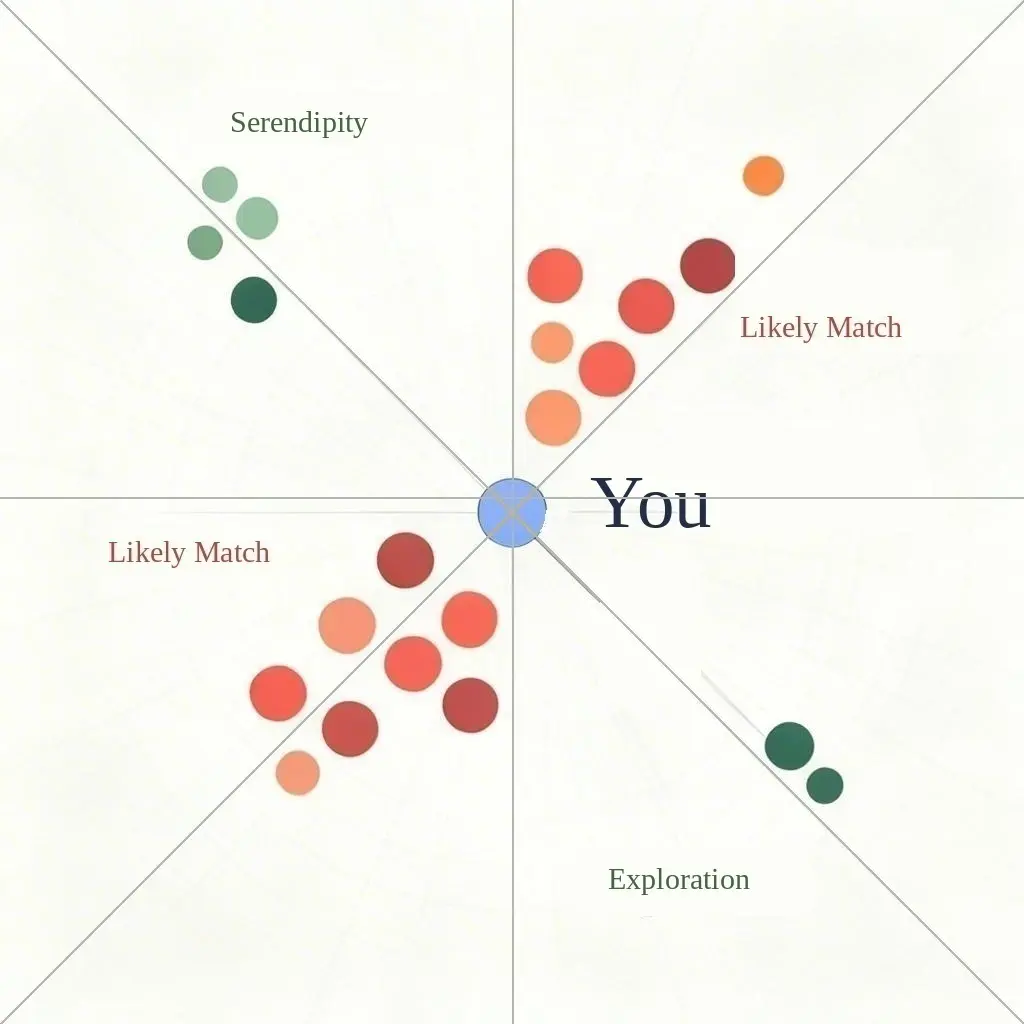
These numbers are used to place you and every movie in the same geometric space. Most of us can visualize a 2D map with an x-axis and y-axis. If your preference for romantic comedy movies is an 8 of 10 (x-axis) and your preference for foreign films is a 6 of 10 (y-axis), most of us could plot those coordinates on a graph.
The challenge is life is much more complicated than 2D. Each new preference category is a new dimension. We’re no longer working in a 2D environment. It might be 500D or 1024D, which becomes impossible to visualize.
Modern AI systems may use thousands of dimensions depending on the architecture. For most recommendation systems, the number of dimensions is a design choice, as there’s a speed and efficiency trade off.
These models don’t ask you to provide your preferences. They infer it by watching your behavior. It doesn’t know you love romantic comedies because you told it. It knows because you watched three of them this week and never hit pause or stop. That process of translating behavior into numbers that represent you is called embedding. (p.s. It doesn’t know about the box of Kleenex beside you on the couch or how much butter you put on your popcorn.)
By representing you and every movie as vectors in a high-dimensional space, Netflix can measure the similarity between your vector and each movie’s vector (typically using something called cosine similarity which measures the angle between them). A cosine similarity closer to 1 means stronger alignment in taste. Netflix can retrieve thousands of nearby candidates in milliseconds (using an approximate nearest-neighbor algorithm) and then refine using a more sophisticated ranking model.
Importantly, this isn’t science fiction. It’s linear algebra applied at scale.
And understanding this gets to the heart of the problem.
Optimization and Convergence

Why does this matter?
It matters because systems built to optimize inevitably converge.
Most sophisticated recommendation systems try to balance two things called Exploitation and Exploration. Exploitation means recommending what they’ve learned you love. Exploration means occasionally recommending something different to see if you love it (that’s where serendipity might arise).
If too much emphasis is put on Exploitation it might feel like your recommendations are becoming narrower.
And recommendation systems don’t just predict behavior, they influence it. It recommended a romantic comedy, you liked it, it recommended another romantic comedy, you liked it. If you are mostly watching romantic comedies, is the AI system influencing your behavior or simply conveying what you love? Or both?
Similarly, if too much emphasis is put on Exploration, the recommendation system might start to feel irrelevant. Why are you showing me horror movies, when I don’t like them. Importantly, irrelevance is likely to achieve the opposite of what the recommendation systems were built to achieve: maximizing engagement, retention, revenue, and lifetime value.
At its core, a recommendation system is a dynamic optimization engine. It continually adjusts parameters to minimize prediction error. It wants to be right, and the more data it gathers, the better it becomes at doing so. Stability is the objective. Convergence is the result.
Over time, convergence can feel like being pigeonholed. You’re accurately categorized, but constrained nonetheless.

And that may feel like you are losing accidental discovery, surprise and serendipity.
Freedom Through Randomness

In a system founded on seeking stability, divergence requires the intentional introduction of randomness.
Or said another way using our explanation above, you need to introduce randomness (or entropy) to shift where you exist in the geometric space.
Let me give an example. Recently, I put a horror movie on Netflix. I muted it and left the room. I returned when the credits were rolling. I don’t like horror movies. They scare me. But I gave it a thumbs up anyway.
Why? I was trying to widen the lens on my Netflix recommendation engine.
Granted one event may not move my taste vector, but escaping a pigeonhole starts with one small act.
Tomorrow night I’ll put on the Dark Night Trilogy when I go to bed, because I stopped loving Batman after Adam West.
There’s no question these recommendation systems are designed to be skeptical of one-off behaviors. But if I do it multiple times, the model will often put more weight on my recent behaviors than my historical ones. “Oh, it looks like preferences have changed and I need to recommend more action and suspense movies.”
Shifting my position in that geometric space changes which movies fall close enough to me to be surfaced. Think of my blue dot above migrating toward the green Serendipity dots to the upper left.
You can also reset or clear your history. I do this on Amazon sometimes. Their recommendation system sees me clicking on Bamboo Mist Tea and recommends I buy it. It does this despite the fact that I am blocked from putting it in my shopping cart. I own the tea company and Amazon won’t let me buy my own product.
If you want to widen the system’s lens, it can be done by intentionally clicking outside your norm, deliberately rating outside your usual preferences, and searching for different categories.
The deeper question is what happens when personalization evolves into identity reinforcement. When a system continuously reflects back your past behavior, it doesn’t just predict who you are, it stabilizes who you become. Convergence can quietly harden preferences into identity.
Watch a few videos about marathon training and your feed fills with endurance athletes; before long, you begin to think of yourself as a runner. Listen to one genre too often and entire categories of music quietly fade from view.
Over time, the system doesn’t just refine your preferences, it changes how you see yourself.
The Case for Intentional Divergence
Recommendation systems are hugely beneficial, but the goals they are optimizing for may diverge from the serendipity, surprise, and accidental discovery that are part of the human experience.
Optimization reduces variance. Variance is where surprise resides.
Choosing randomness is how we regain human agency without abandoning the benefits of recommendation systems.
It doesn’t free us from these systems.
It frees us from self-reinforcement.
After all, these systems reflect the behaviors that represent us. And self-reinforcement makes our behavior reflect the systems. They are designed to converge.
Randomness introduces divergence.
And in that divergence lives something that no recommendation system can compute: the joy of serendipity.
